TLDR
NIH tests effectively measure basic retrieval—like pinpointing a single fact within a large text—but fall short in providing a useful metric for today’s reasoning models. Today’s models need to perform transitive and hierarchical lookup tasks interleaved with reasoning. For example, consider a scenario where the model is given:
Input:
<Initial large context>
<User prompt>
A robust response might look like:
Output:
<think>
Reasoning step A (on preceding input context)
--> Retrieval step A (from preceding input + output context)
--> Reasoning step B (on preceding input + output context)
--> Retrieval step B (from preceding input + output context)
--> Reasoning step C (on preceding input + output context)
--> Retrieval step C
...
</think>
<Synthesized answer displayed to user>
In this case, the model must blend reasoning and multi-hop retrieval across several interdependent steps. This same idea can be extended to hierarchical reasoning and retrieval. NIH falls short in usefully capturing this idea.
What is Needle in a Haystack?
The ‘Needle in a Haystack’ test is a method to gauge how well large language models (LLMs) and retrieval-augmented generation (RAG) systems perform with varying context sizes. It involves hiding a specific detail—the ‘needle’—within a big, complicated chunk of text, called the ‘haystack.’ This concept is visually illustrated in Figure 1.
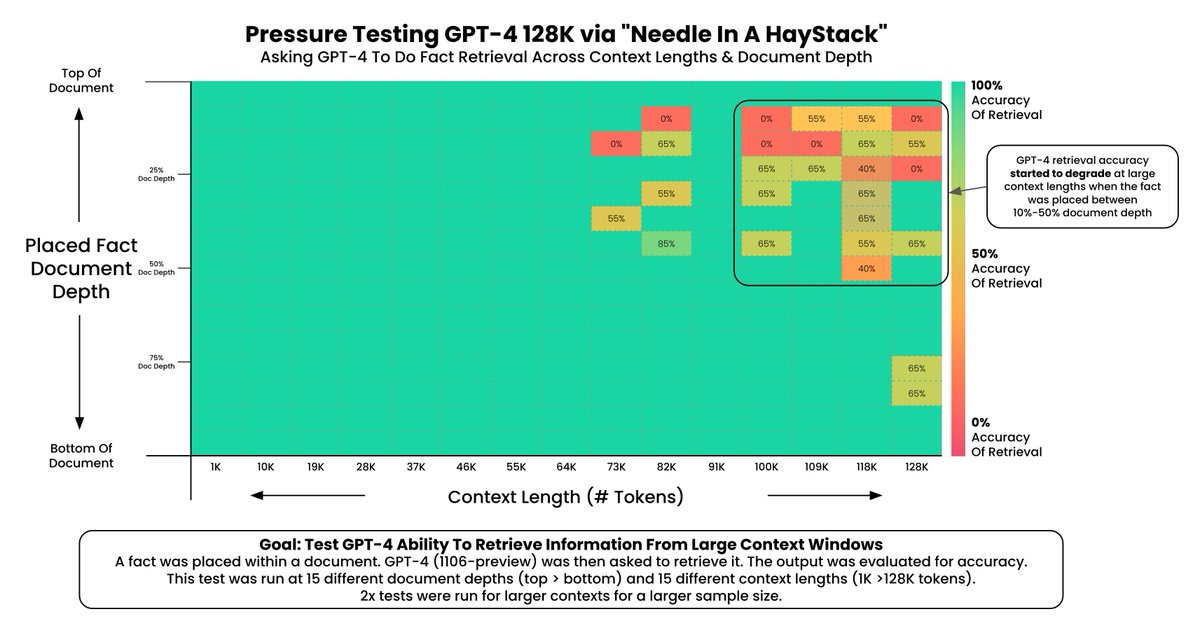
Figure credits to The Needle In a Haystack Test.
The test was popularized by Greg Kamradt, who explored how models handle retrieval in extended texts 1. Today, a widely used version comes from OpenCompass’s NeedleBench, which tests various retrieval and reasoning skills over long contexts 2.
What NIH Performance Shows
Strong results in the Needle in a Haystack (NIH) test mean a model can zero in on specific details in a large text, implying it has a sharp, scalable focus for retrieval. For example, studies show smaller models with memory enhancements can ace NIH tests over 1 million tokens, proving their retrieval precision 3.
What It Doesn’t Show
NIH performance does not indicate that the model can attend to or process multiple distinct pieces of information simultaneously—such as in multi-needle retrieval tasks—reorganize them into a coherent sequence, or reason comprehensively about the entire input context. These capabilities require broader skills that the NIH test is not designed to assess. It’s great at finding one needle, but not at juggling many or understanding the whole haystack.
For instance, NIH can’t assess scenarios where a model must retrieve interconnected facts—like tracing causes and effects across multiple linked documents—or reason about nested or hierarchical information structures.
NIH Benchmark Variations
The OpenCompass NeedleBench framework offers several tasks to test LLMs beyond the basic NIH setup. Here’s a breakdown:
| Task | Description |
|---|---|
| Single-Needle Retrieval Task (S-RT) | Assesses the model’s ability to extract a single key piece of information, testing precision in recalling specific details. |
| Multi-Needle Retrieval Task (M-RT) | Explores the model’s capability to retrieve multiple related pieces of information, simulating complex queries. |
| Multi-Needle Reasoning Task (M-RS) | Evaluates the model’s ability to extract and utilize multiple key pieces, requiring comprehensive understanding. |
| Ancestral Trace Challenge (ATC) | Tests multi-layer logical reasoning using all critical content in the text. |
These tasks, detailed in NeedleBench documentation 2, show that while basic NIH (like S-RT) focuses on one needle, advanced tests probe deeper skills that standard NIH doesn’t cover.