Watch the animation above for a few seconds. Your brain is already trying to figure out the rule – which row comes next, what the pattern is doing, whether it’s random or structured. You can’t help it. Humans are compulsive pattern learners: we see a sequence, and we immediately start building a mental model of the underlying dynamics.
But what computation is your brain actually performing when it does this? That’s the question I set out to answer for my solo final project in MIT 9.660 (Computational Cognitive Science). Following Marr’s computational level of analysis, I built a Bayesian program-induction model as a formal theory of human rule inference, ran a behavioral experiment to measure how real people reason about evolving patterns, and compared the two. The results suggest that human cognition does something that looks a lot like probabilistic inference over a structured “language of thought” for rules – but with the messy, bounded constraints you’d expect from a brain with limited working memory.
What Are Cellular Automata?
Four types of cellular automata. From left to right: Fixed (dies out), Periodic (repeating), Chaotic (random-looking), and Complex (structured but unpredictable). All from the same simple idea -- each row depends on the row above it.
I needed a domain where the rules are simple, deterministic, and visually interpretable – something where I could precisely control what people see and measure how they reason about it. Cellular automata are perfect for this. You have a row of black and white cells, and a hidden rule determines the next row based on each cell and its two neighbors. That’s it. But depending on which of the 256 possible rules you pick, you get everything from trivially predictable patterns to total visual chaos. Stephen Wolfram categorized them into four complexity classes, shown above – a natural difficulty ladder for studying human inference.
The Experiment

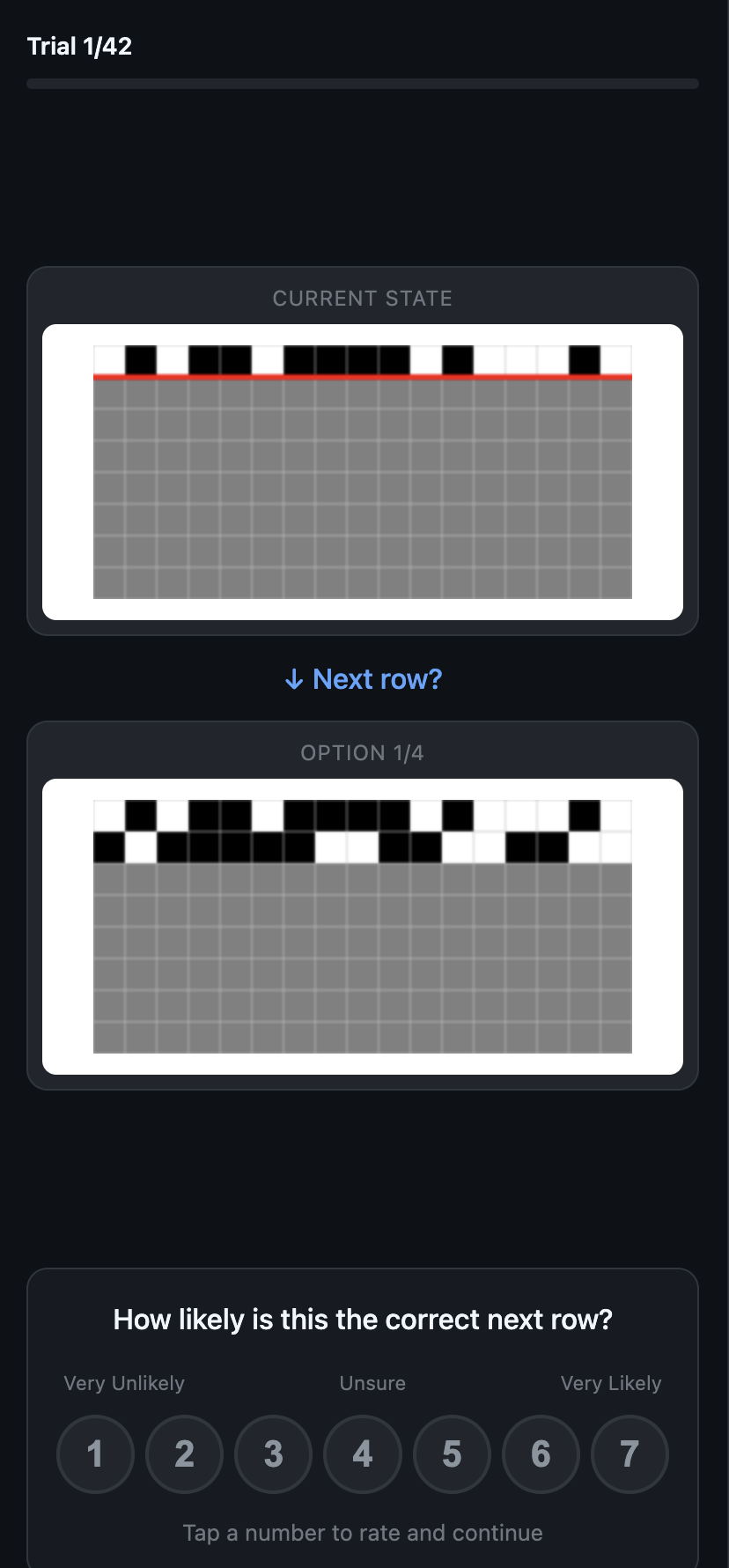
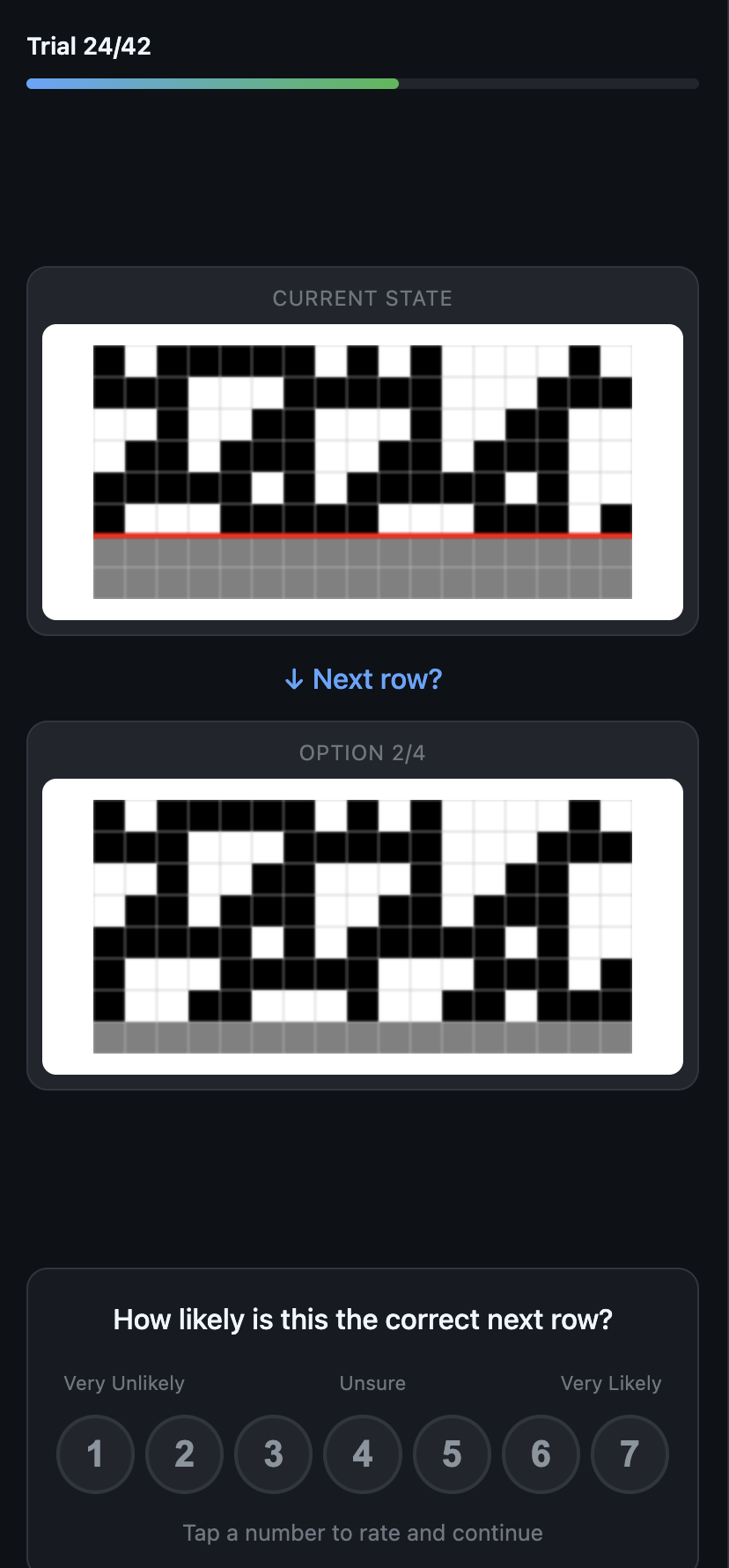
The web experiment. Left: start page. Center: an early trial with just one row of evidence. Right: a later trial with six rows of a chaotic rule.
To study how people actually reason about these patterns, I built a browser-based experiment and ran five participants through it. They watched CA patterns grow one row at a time across 7 different rules spanning all four Wolfram classes. At each time step, they saw four candidate continuations and rated how likely each one was on a 1-7 confidence scale. This gave me graded belief measurements – not just “right or wrong,” but how sure someone was at each point.
You can try the experiment yourself – pay attention to how your own confidence shifts as more rows appear.
What We Learned About Human Reasoning
The first thing that jumps out: people are genuinely good at this. Averaging 59% accuracy where random guessing gets you 25%, participants were clearly learning the underlying structure of the rules, not just guessing. And their confidence grew steadily as more evidence accumulated – from “I have no idea” at one row to “I’m pretty sure” by six rows. That’s exactly the signature of sequential belief updating.
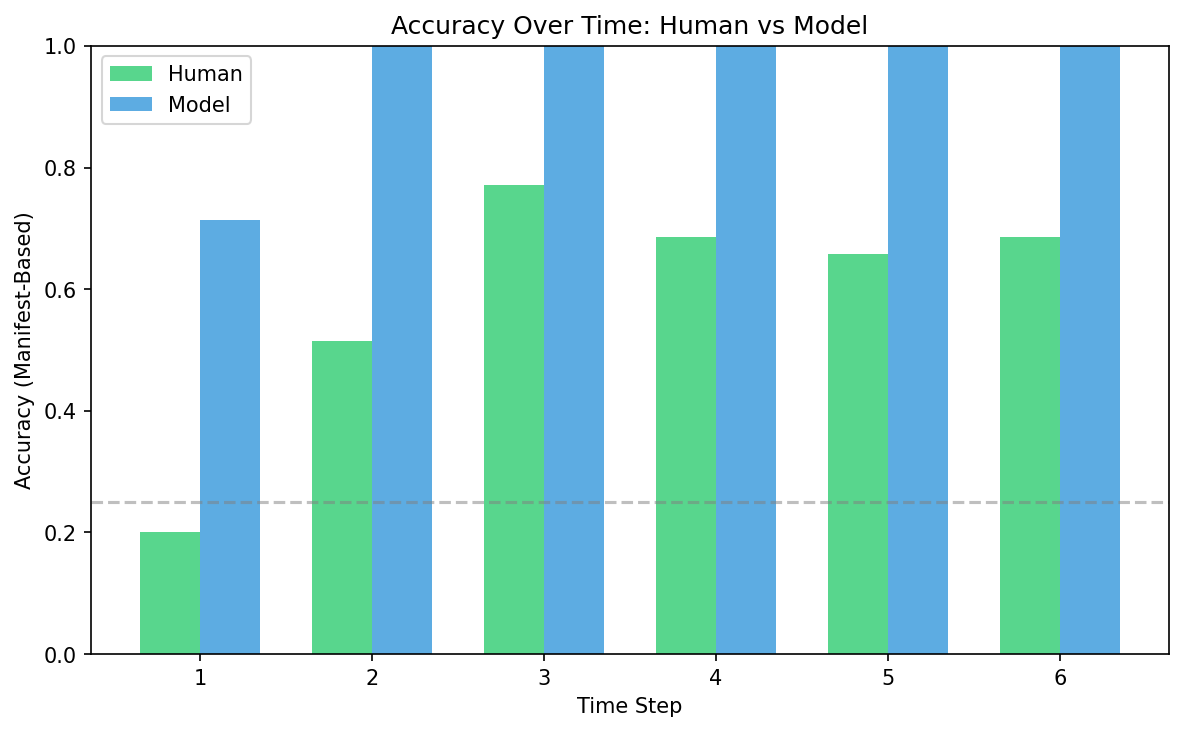
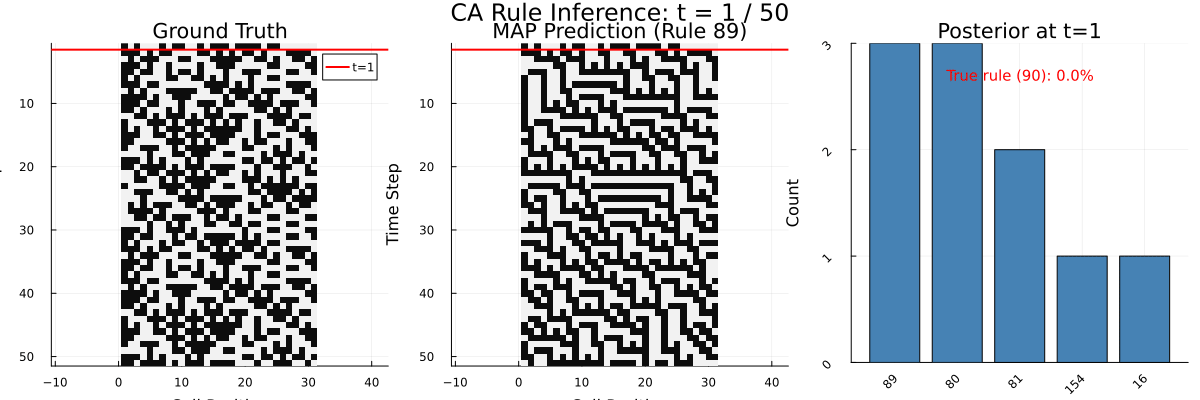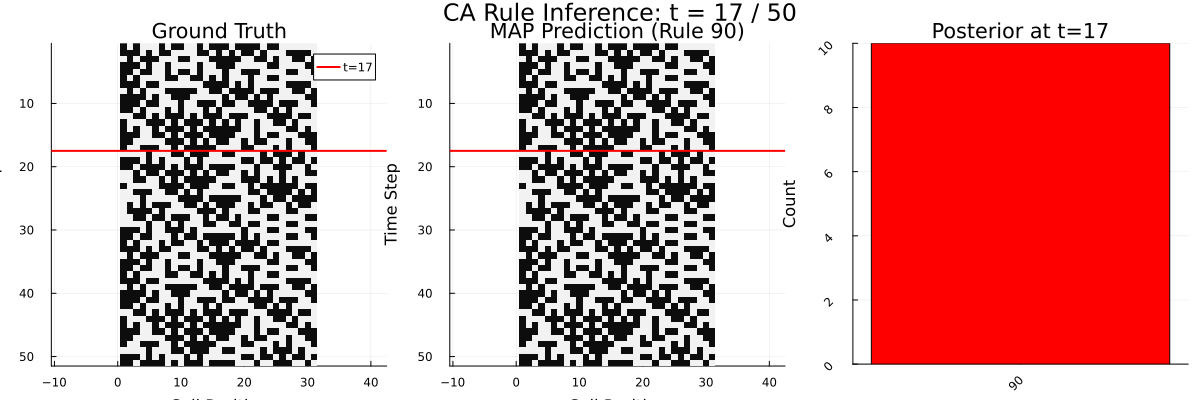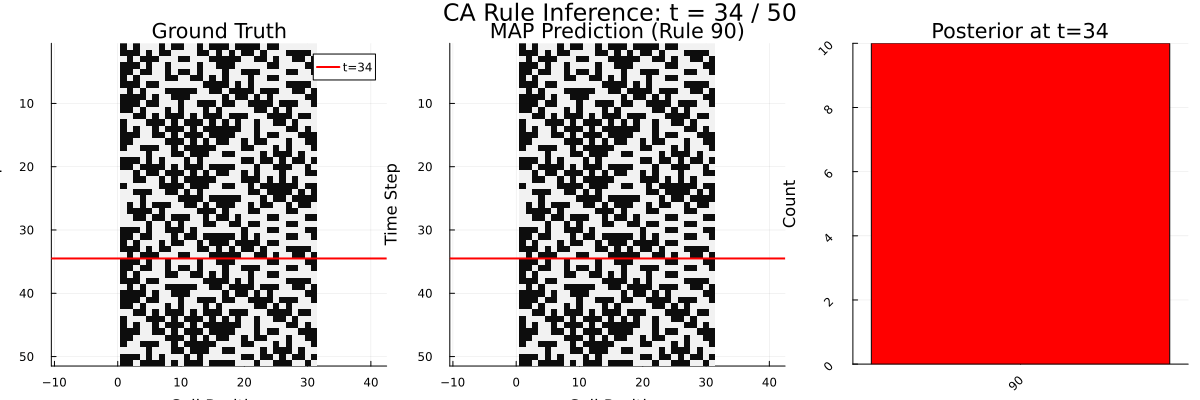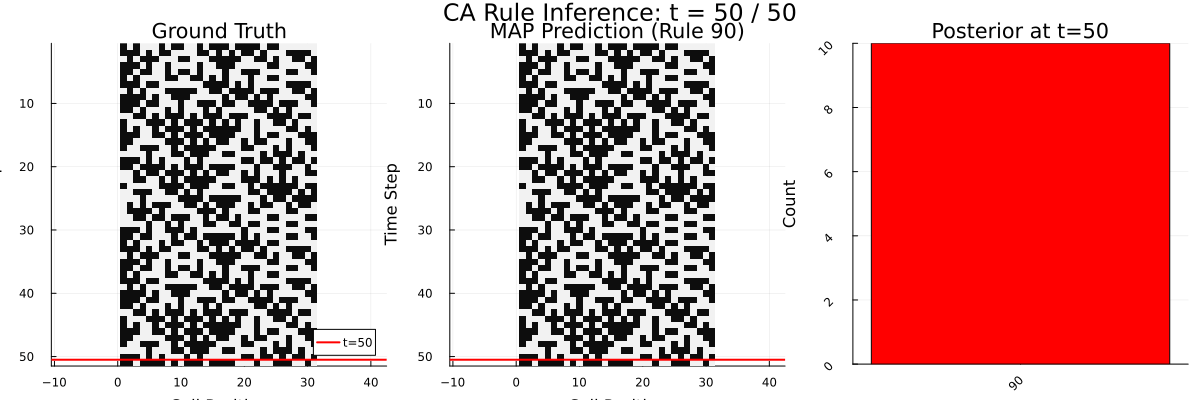
To understand what computation might explain this behavior, I built a Bayesian program-induction model in Gen.jl. It maintains a population of candidate rule hypotheses (represented as Boolean syntax trees in a probabilistic grammar) and updates its beliefs each time a new row appears, using Sequential Monte Carlo with MCMC rejuvenation. Think of it as a formal theory of what the brain might be doing: searching over a structured space of possible rules and updating beliefs as evidence comes in.
The human-model correlation (Pearson r = 0.39) tells us something meaningful: options that the Bayesian model considers likely tend to receive higher human confidence ratings too. People aren’t doing Bayesian inference perfectly – but their reasoning tracks the Bayesian posterior at a coarse level. The learning curves have the same shape, the evidence accumulation dynamics look similar, and both show increasing confidence over time.
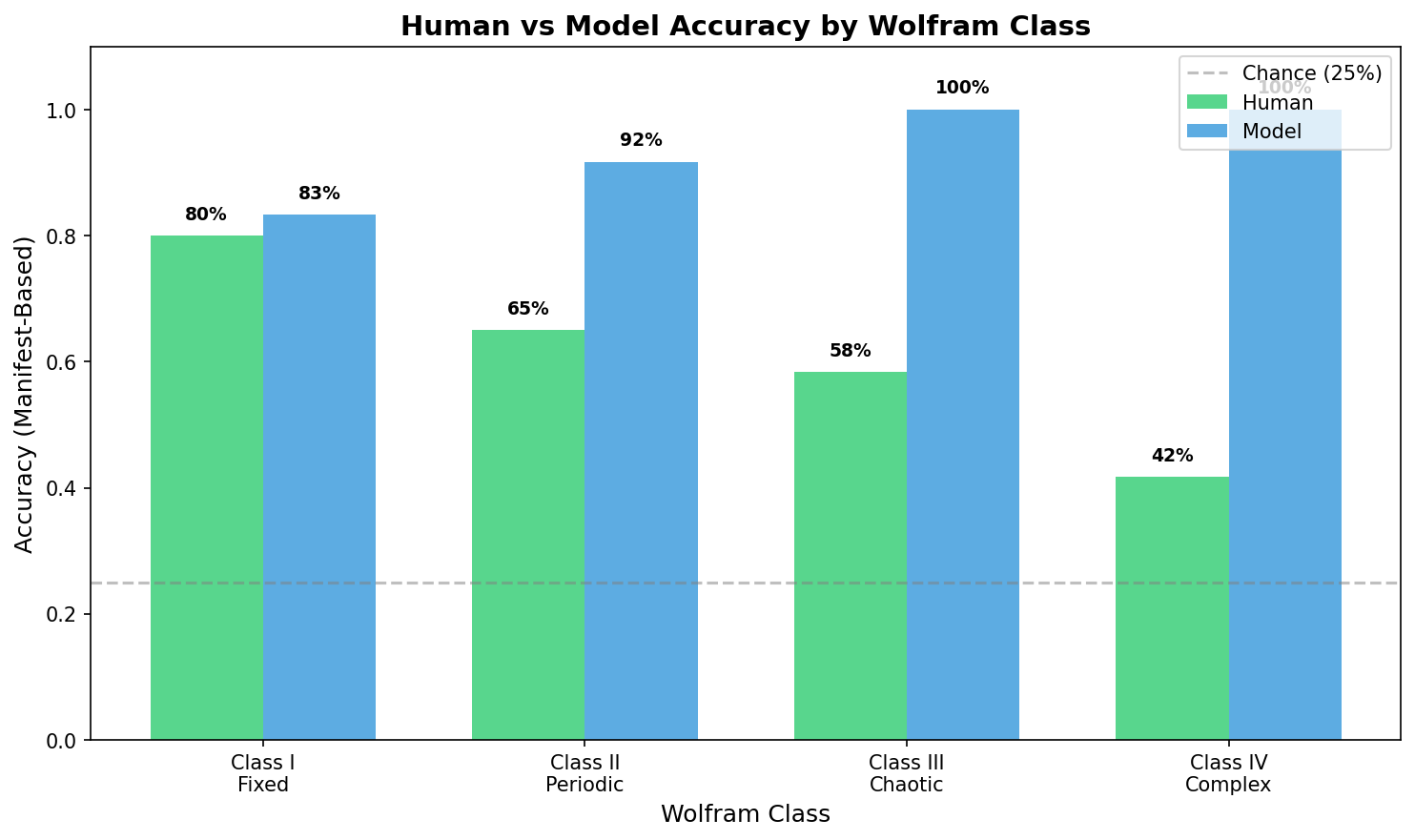
The most interesting part is where humans and the model diverge. For simple Fixed-point rules (Class I), both humans and the model perform around 80% – nearly identical. But as the patterns get more complex and chaotic, the gap widens dramatically: humans drop to 42% on Class IV (Complex) rules while the model hits 100%. This isn’t a flaw in human reasoning – it’s a signature of what cognitive scientists call resource-rational cognition. Our brains are doing something approximately Bayesian, but with real constraints: limited working memory, noisy attention over a 17-cell grid, and a tendency to commit to a single hypothesis rather than maintaining a full distribution. The chaotic and complex patterns overwhelm those constraints in exactly the way the theory predicts.